声明:我已委托「维权骑士」(rightknights.com)为我的文章进行维权行动。
为什么需要垃圾回收?
在程序运行时,程序为了计算需要,往往会申请一大块的内存空间,将它们分配给相应的变量。 当程序执行结束后(准确的说是相关变量使用完毕,例如,对于函数中的局部变量而言,这个时刻可能是对应的函数调用结束),相关的内存不再使用,需要对这块区域进行垃圾回收。 进行垃圾回收的好处是可以保证程序在运行过程中,内存资源不会过于紧张,在一定程度上减少 内存泄漏(Memory Leak) 的产生。
在不同的程序中,设计者对垃圾回收的处理是不同的,例如在C/C++中,开发人员需要自己手动的申请、管理内存:通过new 关键字申请相应的内存;当使用的内存使用完毕后,需要自己通过delete关键字手动释放内存。如果开发过程中,开发人员使用了一块内存而忘记去释放它,很容易造成内存泄露。相比C/C++,Java在垃圾回收方面做足了功课,JVM自带垃圾收集器,提供定期的垃圾回收功能,帮助开发人员更专注于程序的开发。
垃圾回收概况
如果系统需要回收一块区域的内存,通常需要两步:
- 表示某些内存区域为垃圾区域
- 对标识为垃圾的区域进行回收操作
垃圾标记方法
市面上常见的垃圾标识算法主要分为两种:引用计数算法 和 根搜索算法。
引用计数算法
引用计数算法是垃圾标记方法中最简单有效的方法,在一定程度上可以找到内存中大部分的垃圾区域。
具体实现
每一个对象中,会有一个无符号整数的字段(例如ref_count),他标识的含义是当前有多少对象引用了当前对象。当对象初次分配时,ref_count=1;每将这个对象付给变量时,ref_count将会加1;当某个变量不在指向目标对象时,对应对象的ref_count将减一。当ref_count等于0时,对应的内存可以进行释放了。
在以下代码中,各个对象的ref_count如注释所示:
object_1 = new A(); // ref_count(object_1) = 1
object_2 = new A(); // ref_count(object_2) = 1
object_1.next = object_2; // ref_count(object_2) = 2
object_1 = null; // ref_count(object_1) = 0 => 回收原来的object_1
// => ref_count(object_2) = 1
object_2 = null; // ref_count(object_2) = 0 => 回收原来的object_2
优缺点
-
👍 引用计数算法具有以下优点:设计简单,回收垃圾的速度快。因为每个对象都有一个字段表示对应对象的被引用数,当被引用数为0时,可以立即进行垃圾回收,执行效率高。
-
👎 引用计数算法的缺点也是显而易见的,我们无法通过解决下面循环引用的问题。
object_1 = new A(); // ref_count(object_1) = 1
object_2 = new A(); // ref_count(object_2) = 1
object_1.next = object_2; // ref_count(object_2) = 2
object_2.next = object_1; // ref_count(object_1) = 2
object_1 = null; // ref_count(object_1) = 1 => 无法回收原来的object_1
object_2 = null; // ref_count(object_2) = 1 => 无法回收原来的object_2
而且,每个对象都需要一个字段表示被引用数,为了可以表示机器中所有可能的引用当前对象的数量,这个字段位数的可能很大。例如在一台32位的机器上,指向某一个地址的引用可能有2^32种,所以这个字段需要32位。对于一些本身就很小的对象,而言,这种代价开销实在太大了。
根搜索算法
在根搜索算法中,所有的对象均看作图中的点,对象之间的引用关系我们视为点之间的有向边。定义图中的若干点为GC Root,以这些点作为起点,对这个有向图进行遍历。当一次遍历结束时,图中的一个点没有被遍历到,那么这个点表示的对象应该被视为无用的垃圾对象,进行回收。这种搜索算法可以有效的解决之前提到的循环引用问题,因为对于循环引用的垃圾对象,我们无法找到一条路径,始于GC Root,终(经)于这些对象。
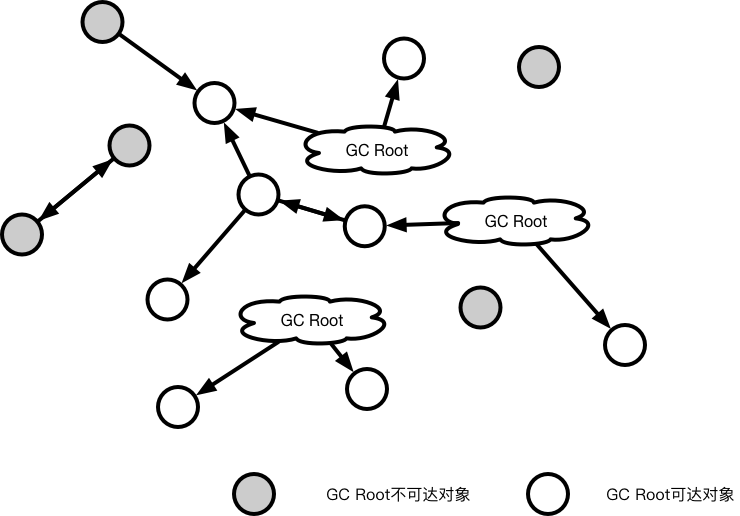
优缺点
-
👍 根搜索算法实现比较简洁,同时对于对象本身而言,需要额外添加的标记字段空间要求比较小。不考虑字节对齐,字段只需要一位即可,被主流的商用程序语言(例如Java、C#等)使用。
-
👎 每一次根搜索算法都要对整个内存空间进行一次较为完整的遍历,当内存空间较大,对象较多,引用关系复杂时,对应的时间复杂度也会提升,效率较低。
JVM中的根搜索算法
java中的引用
在正式介绍JVM中的根搜索算法前,我们需要了解一些Java中常见的引用类型。
强引用
强引用(StrongReference)是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
软引用
如果一个对象只具有软引用(SoftReference),则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
软引用可用来实现内存敏感的高速缓存。
弱引用
弱引用(WeakReference)与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。
在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
虚引用
“虚引用(PhantomReference)”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
可以做GC Roots的对象
在Java语言里,可作为GC Roots的对象包括下面几种:
- 虚拟机栈(栈帧中的本地变量表)中的引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中的常量引用的对象。
- 本地方法栈中JNI(即一般说的Native方法)的引用的对象。
常见的垃圾回收算法
垃圾回收算法在具体实现上可以分为标记-清除(Mark-Sweep)算法、复制(Copy)算法以及标记整理(Mark-Compact)算法。
标记-清除(Mark-Sweep)算法
算法内容
标记-清除算法 将垃圾回收分为两个阶段:
- 标记阶段:标记出所有需要回收的对象。具体算法细节可以参考上面的
垃圾标记方法。 - 清除阶段:标记完成后,统一回收被标记的对象
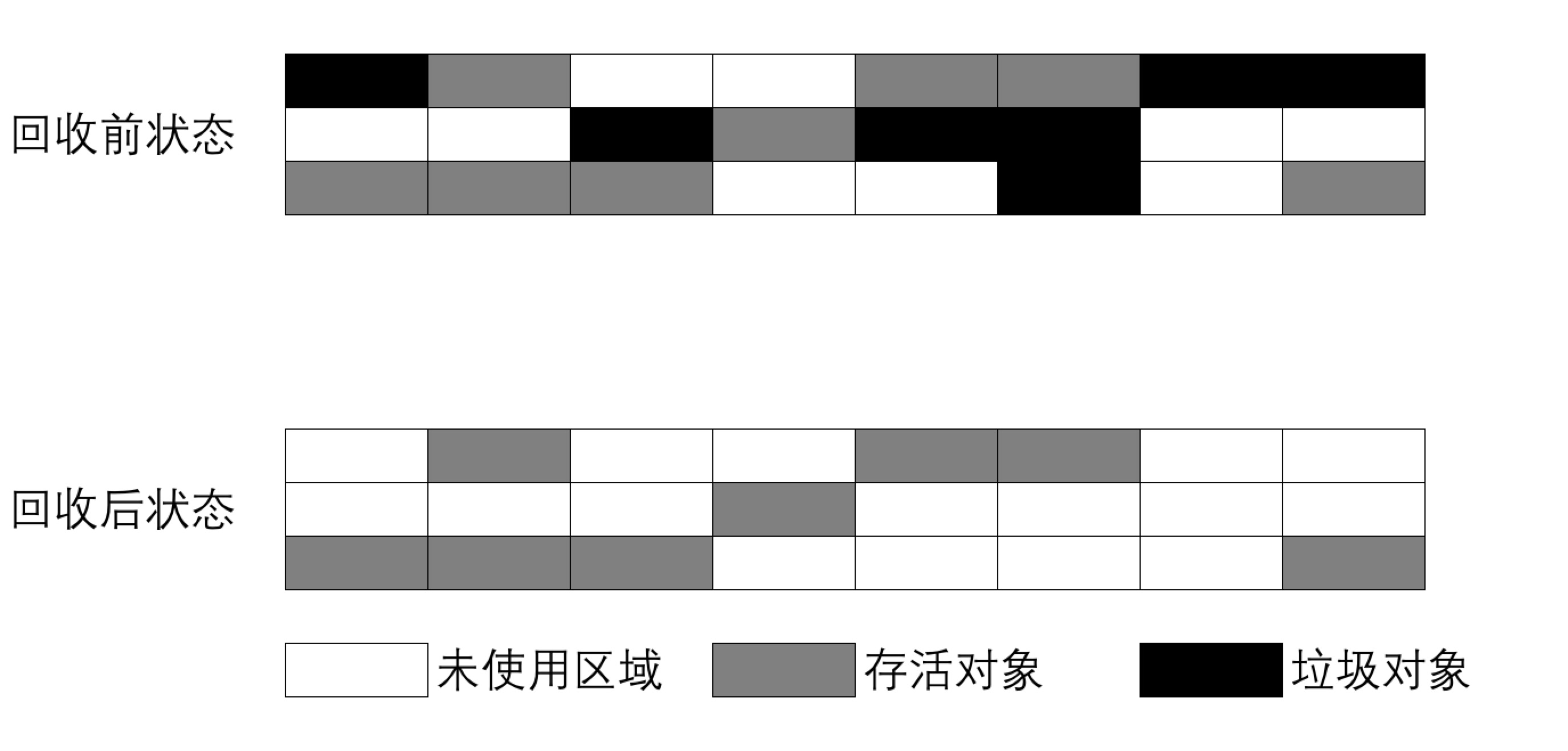
优缺点
- 👎 标记清除过程效率都不高。
- 👎 由于对象之前在内存中的分布是无规律的,所以标记清除之后会产生大量的不连续的内存碎片,可能造成在连续的大内存空间缺失,
阻碍大内存对象的分配,严重时会触发垃圾回收,甚至出现OutOfMemeryError。
复制(Copy)算法
复制算法相比标记-清除算法,在一定程度上就不容易出现上述问题。
算法内容
- 复制算法将内存划分为两个区域,在任意时间点,所有动态分配的对象都只能分配在其中一个区间(称为活动区间),而另外一个区间(称为空闲区间)则是空闲的。
- 当系统进行GC操作时,系统会将活动区间内的存活对象,全部复制到空闲区间,且严格按照内存地址依次排列,同时将更新存活对象的内存引用地址指向新的内存地址。
- 在GC之后,原来的活动区域变为空闲区域,而空闲区域变成活动区域。两个区域周而复始,变换着自己的角色。
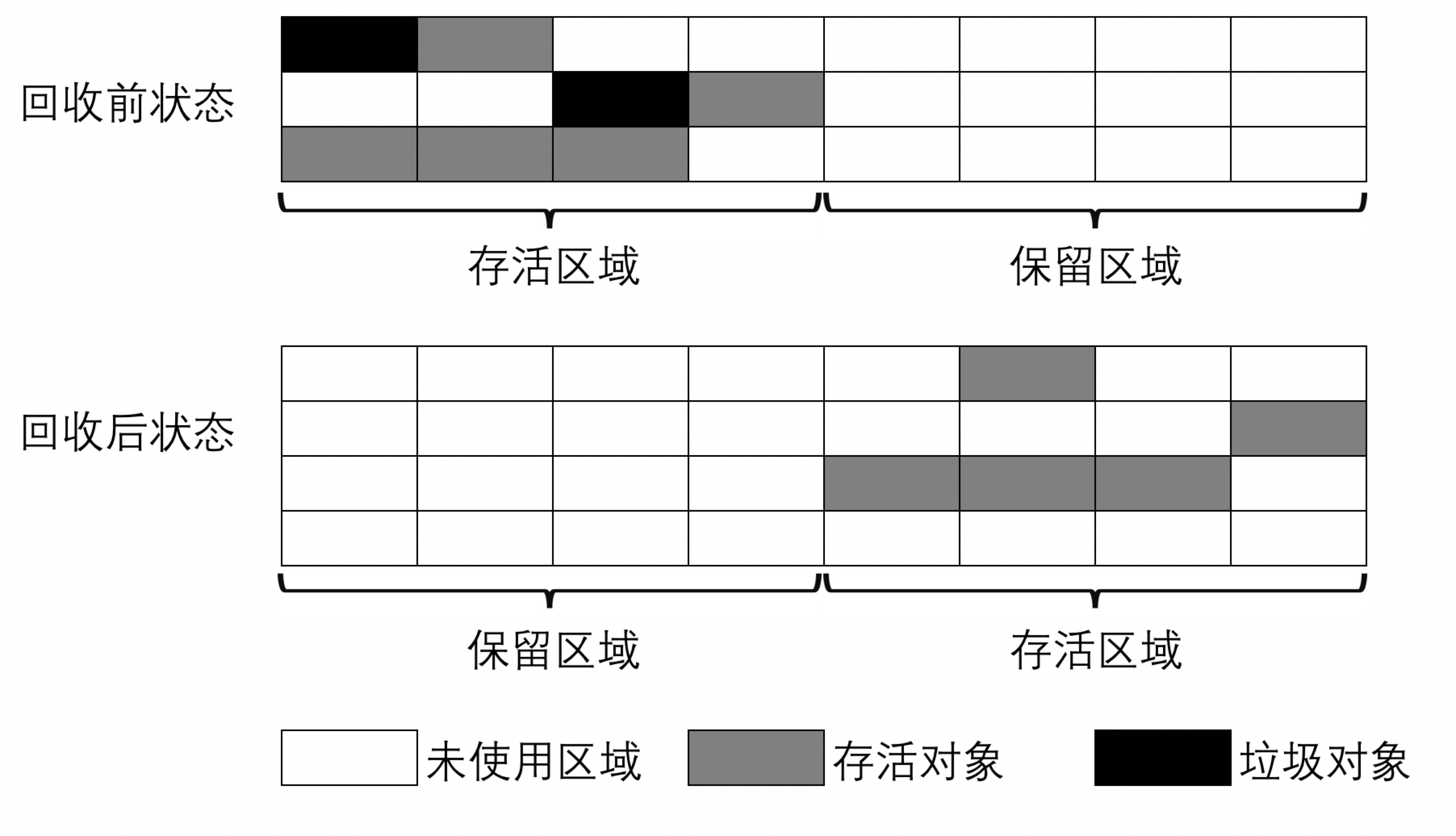
优缺点
- 👍虽然复制算法弥补了标记-清除算法内存布局混乱的缺点,但缺点也是相当明显的:
- 👎复制算法是以牺牲一半的内存作为换取内存布局整齐的代价。
- 👎当内存中存在着一些对象他们的存活时间比较长时,大量的拷贝工作将会降低系统的运行效率。
标记-整理(Mark-Compact)算法
算法内容
标记-整理算法(部分文章也成“标记-清除-整理算法”)结合了“标记-清除”和“复制”两个算法的优点,是以上两种方案的折中,也分为两个阶段。
- 标记阶段:标记出所有需要回收的对象。具体算法细节可以参考上面的
垃圾标记方法。 - 整理阶段:待清除未标记存活对象,并将存活对象“压缩”到堆的其中一块,按顺序排放。
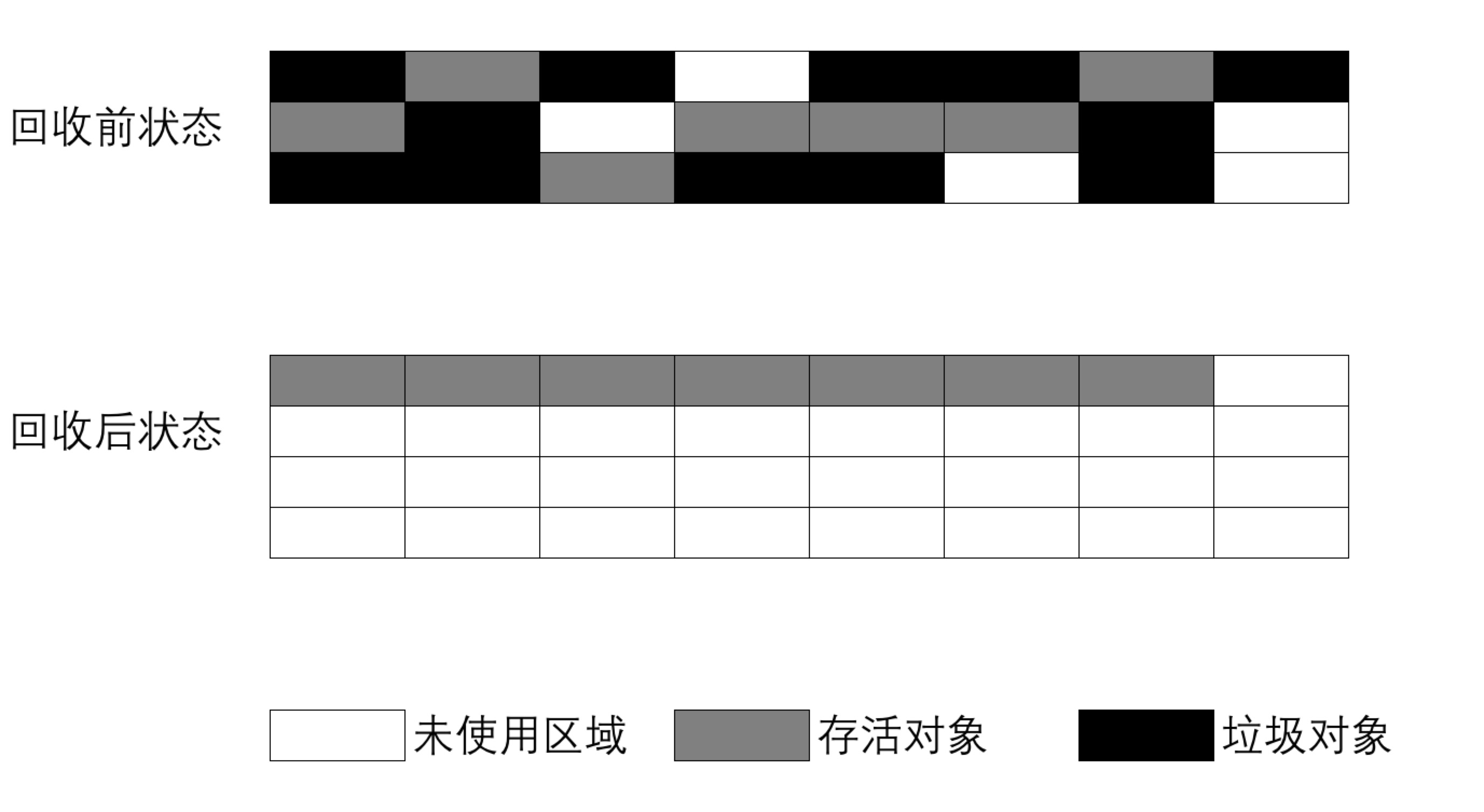
优缺点
- 👍 此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
- 👎 标记-整理算法缺点就是效率不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
参考资料